Spinnaker is a great tool for continuous deployment of services into Kubernetes. It has a lot of first-class integration support for things like Docker containers and Google Cloud Storage blobs.
For example, say you have a Docker container that gets deployed to Kubernetes via a Helm-chart-style manifest. You might store the manifest in Google Cloud Storage and the Docker container in Google Cloud Registry. Change one of those things, it triggers a pipeline to deploy.
This is not so easy if you are in Azure and storing your manifests in Azure Blob Storage. You can make this work, but it takes a lot of moving pieces. I’ll show you how to get this done.
“Why Don’t You Just…?”
Before we get into the “how,” let’s talk about “why.”
You might wonder why I’m interested in doing any of this when there are things like Azure DevOps that can do deployment and Azure Helm Repository to store Helm charts. Just sidestep the issue, right?
Azure DevOps is great for builds but doesn’t have all the deployment features of Spinnaker. In particular, if you want to use things like Automated Canary Analysis, Azure DevOps isn’t going to deliver.
Further, Azure DevOps is kind of a walled garden. It works great if you keep everything within Azure DevOps. If you want to integrate with other tools, like have artifacts stored somewhere so another tool can grab it, that’s hard. Azure DevOps can publish artifacts to various repo types (NuGet, npm, etc.) but really has no concept of artifacts that don’t get a semantic version (e.g., stuff that would happen in a continuous delivery environment) and aren’t one of the supported artifact types. Universal packages? They need semantic versions.
So what if you have a zip file full of stuff that just needs to be pushed? If Azure DevOps is handling it in a pipeline, you can download build artifacts via a pipeline task… but from an external tool standpoint, you have to use the REST API to get the list of artifacts from the build and then iterate through those to get the respective download URL. All of these calls need to be authenticated but at least it supports HTTP Basic auth with personal access tokens. Point being, there’s no simple webhook.
Azure Helm Repository is currently in beta and has no webhook event that can inform an external tool when something gets published. That may be coming, but it’s not there today. It also doesn’t address other artifact types you might want to handle, like that arbitrary zip file.
How It Works
Now you know why, let me explain how this whole thing will work. There are a lot of moving pieces to align. I’ll explain details in the respective sections, but so you get an overview of where we’re going:
- Publishing a new/updated blob to Azure Blob Storage will raise an event with Azure EventGrid.
- A subscription to Azure EventGrid for “blob created” events will route the EventGrid webhooks to an Azure API Management endpoint.
- The Azure API Management endpoint will transform the EventGrid webhook contents into a Spinnaker webhook format and forward the transformed data to Spinnaker.
- Spinnaker will use HTTP artifacts to download the Azure Blob.
- The Spinnaker download request will be handled by a small Node.js proxy that converts HTTP Basic authentication to Azure Blob Storage “shared key” authentication.
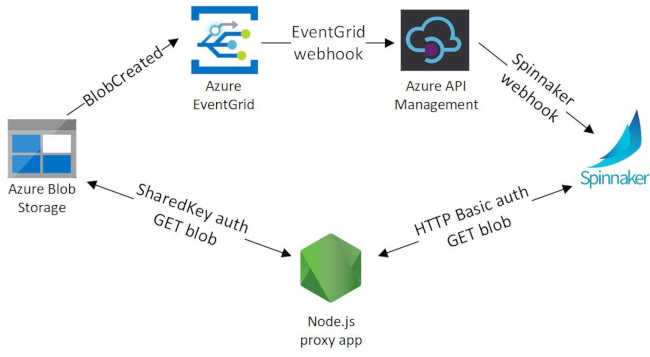
Most of this is required because of the security around EventGrid and Azure Blob Storage. There’s not a straightforward way to just use a series of GET and POST requests with HTTP Basic auth.
Create the Azure Storage Account and Blob Container
This is where you will store your artifact blobs.
az storage account create \
--name myartifacts \
--resource-group myrg \
--access-tier StandardLRS \
--https-only true \
--kind StorageV2 \
--location westus
az storage container create \
--name artifacts \
--account-name myartifacts
Your blobs will get downloaded via URLs like https://myartifacts.blob.core.windows.net/artifacts/artifact-name.zip.
Create a Basic Auth Proxy for Blob Storage
If you want to download from Azure Blob Storage without making the artifacts publicly accessible, you need to use SharedKey authentication.. It looks a lot like HTTP Basic but instead of using a username/password combination, it’s a username/signature. The signature is generated by concatenating several headers and generating a signature using your shared key (available through the Azure portal).
It’s complicated and not something built into Spinnaker. If you really want to see how to generate the signature and all that, the docs have a very detailed explanation.
The short version here is that you probably want a client SDK library to do this work. Since Spinnaker really only supports HTTP Basic anyway, you need to take in username:password in some form and convert that into the request Blob Storage expects.
Richard Astbury has a great blog article showing a simple web server that takes in HTTP Basic auth where your storage account name is the username and the storage account key is the password, then proxies that through to Blob Storage for download.
Deploy this proxy somewhere you can access like an Azure App Service.
I converted this to be an Express app without too much trouble, which adds some logging and diagnostics to help with troubleshooting.
Things to keep in mind when you deploy this:
- Run in HTTPS only mode using a minimum TLS 1.2. These are options in the Azure App Service settings. You’ll be using HTTP Basic auth which isn’t encrypted, so ensuring the communication itself is encrypted is important.
- Consider adding more layers of security to ensure random people can’t just use your proxy. Azure App Service apps are public, so consider updating the app to only respond to requests to a special endpoint URL that contains a key only you know. You could also ensure you only respond to requests for known storage account info, not just ay info. That would mean folks need the special endpoint URL and the storage account info to get anything.
- Ensure it’s “always on.” Azure App Service apps go to sleep for a while when they’re idle. The first request can time out as it wakes up, and if Spinnaker is the first request it’ll cause a pipeline failure.
For this walkthrough, we’ll say your Blob Storage proxy app is at https://mycoolproxy.azurewebsites.net. You’ll see this show up later as we set up the rest of the pieces. When Spinnaker wants to download an HTTP artifact, it’ll access https://mycoolproxy.azurewebsites.net/artifacts/artifact-name.zip instead of accessing the Blob Storage URL directly.
You should now be able to access an Azure Blob Storage blob via your proxy using HTTP Basic authentication. Verify this works by dropping a blob into your artifact storage and downloading it through the proxy.
Enable Spinnaker Webhook Artifacts
Spinnaker needs to know that it can expect artifacts to come in via webhooks. To do that, you need to enable the artifacts. Edit the .hal/default/profiles/echo-local.yml file to enable it.
webhooks:
artifacts:
enabled: true
Enable Spinnaker HTTP Artifacts
The webhook will tell Spinnaker where the artifact lives, but you have to also enable Spinnaker to download the artifact. You also have to provide it with credentials to do so. There is good doc explaining all this but here’s a set of commands to help you.
hal config features edit --artifacts true
hal config artifact http enable
USERNAME=myartifacts
PASSWORD=[big long shared key from Azure Portal]
echo ${USERNAME}:${PASSWORD} > upfile.txt
hal config artifact http account add myartifacts \
--username-password-file upfile.txt
# You're stuck with that upfile.txt in the current folder until you
# do a backup/restore of the config. First deploy it to get the changes
# out there...
hal deploy apply
# Now back up the config.
hal backup create
# Immediately restore the backup you just made.
hal backup restore --backup-path halbackup-Tue_Dec_18_23-00-10_GMT_2018.tar
# Verify the local upfile.txt isn't being used anymore.
hal config artifact http account get myartifacts
# Assuming you don't see a reference to the local upfile.txt...
rm upfile.txt
Spinnaker now knows not only that webhooks will be supplying artifact locations, but also how to provide HTTP Basic credentials to authenticate with the artifact source.
At the time of this writing I don’t know how Spinnaker handles multiple sets of credentials. For example, if you already have some HTTP Basic artifact credentials set up and add this new set, how will it know to use these new creds instead of the ones you already had? I don’t know. If you know, chime in on this GitHub issue!
You should now have enough set up to enable Spinnaker to download from Azure Blob Storage. If an artifact URL like https://mycoolproxy.azurewebsites.net/artifacts/artifact-name.zip comes in as part of an HTTP File artifact, Spinnaker can use the supplied credentials to download it through the proxy.
Create an API Management Service for EventGrid Handling
Azure API Management Service is usually used as an API gateway to allow you to expose APIs, secure them, and deal with things like licensing and throttling.
We’re going to take advantage of the API Management policy mechanism to handle Azure EventGrid webhook notifications. This part is based on this awesome blog article from David Barkol. Using API Management policies enables us to skip having to put another Node.js proxy out there.
Why not use API Management for the Blob Storage proxy? I wasn’t sure how to get the Azure Blob Storage SDK libraries into the policy and didn’t want to try to recreate the signature generation myself. Lazy? Probably.
The API Management Service policies will handle two things for us:
- Handshaking with EventGrid for webhook subscriptions. EventGrid doesn’t just let you send webhooks wherever you want. To set up the subscription, the receiver has to perform a validation handshake to acknowledge that it wants to receive events. You can’t get Spinnaker to do this, and it’s nigh impossible to get the manual validation information.
- Transforming EventGrid schema to Spinnaker Artifact schema. The data supplied in the EventGrid webhook payload isn’t something Spinnaker understands. We can’t even use Jinja templates to transform it at the Spinnaker side because Spinnaker doesn’t want an inbound webhook to be an array - it wants the webhook to be an object that contains the array in a property called
artifacts. We can do the transformation work easily in the API Management policy.
First, create your API Management service.
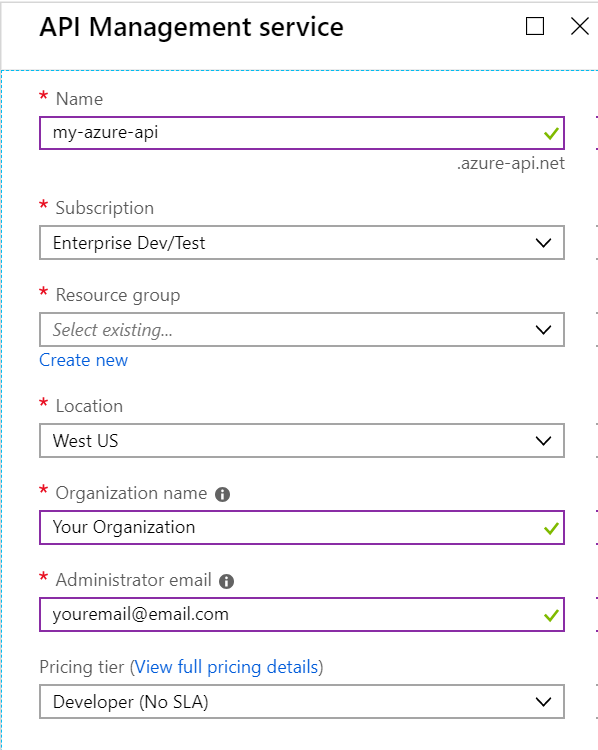
This can take a long time to provision, so give it a bit. When it’s done, your API will be at a location based on the API Management Service name, like https://my-azure-api.azure-api.net. All the APIs you hang off this management service will be children of this URL.
Once it’s provisioned, go to the “APIs” section. By default, you’ll get a sample “Echo” API. Delete that.
Now, add a new “Blank API.” Call it “EventGrid Proxy” and set the name to eventgrid-proxy. For the URL scheme, be sure to only select HTTPS. Under “Products,” select “Unlimited” so your developer key for unlimited API calls will be in effect.
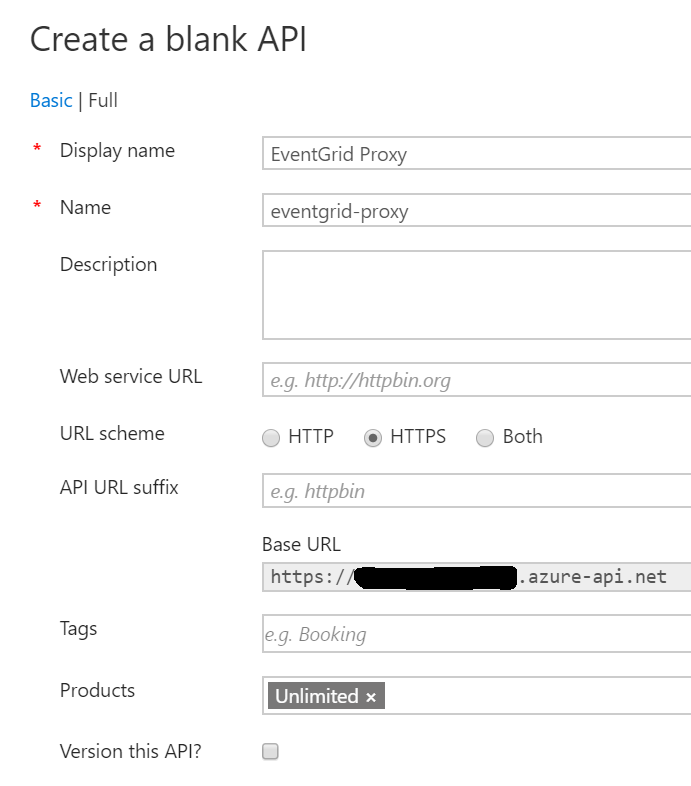
In the EventGrid Proxy API, create a new operation called webhook that takes POST requests to /webhook.
The webhook operation doesn’t do anything except give us a valid endpoint to which EventGrid can post its webhook notifications.
On the EventGrid Proxy api, select “Design” and then click the little XML angle brackets under “Inbound Processing.” This will get you into the area where you can set up and manage API policies using XML.
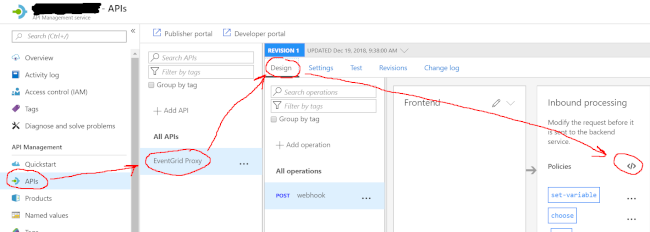
In the inbound policy, paste this XML beauty and update the noted locations with your endpoints:
<policies>
<inbound>
<set-variable value="@(!context.Request.Headers.ContainsKey("Aeg-Event-Type"))" name="noEventType" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<bool>("noEventType"))">
<return-response>
<set-status code="404" reason="Not Found" />
<set-body>No Aeg-Event-Type header found.</set-body>
</return-response>
</when>
<otherwise>
<set-variable value="@(context.Request.Headers["Aeg-Event-Type"].Contains("SubscriptionValidation"))" name="isEventGridSubscriptionValidation" />
<set-variable value="@(context.Request.Headers["Aeg-Event-Type"].Contains("Notification"))" name="isEventGridNotification" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<bool>("isEventGridSubscriptionValidation"))">
<return-response>
<set-status code="200" reason="OK" />
<set-body>@{
var events = context.Request.Body.As<string>();
JArray a = JArray.Parse(events);
var data = a.First["data"];
var validationCode = data["validationCode"];
var jOutput =
new JObject(
new JProperty("validationResponse", validationCode)
);
return jOutput.ToString();
}</set-body>
</return-response>
</when>
<when condition="@(context.Variables.GetValueOrDefault<bool>("isEventGridNotification"))">
<send-one-way-request mode="new">
<!-- Replace this with YOUR Spinnaker location! -->
<set-url>https://your.spinnaker.api/webhooks/webhook/azureblob</set-url>
<set-method>POST</set-method>
<set-header name="Content-Type" exists-action="override">
<value>application/json</value>
</set-header>
<set-body>@{
var original = JArray.Parse(context.Request.Body.As<string>());
var proxied = new JArray();
foreach(var e in original)
{
var name = e["subject"];
// Replace this with YOUR Blob and proxy info!
var reference = e["data"]
.Value<string>("url")
.Replace("myartifacts.blob.core.windows.net",
"mycoolproxy.azurewebsites.net");
var transformed = new JObject(
new JProperty("type", "http/file"),
new JProperty("name", name),
new JProperty("reference", reference));
proxied.Add(transformed);
}
var wrapper = new JObject(new JProperty("artifacts", proxied));
var response = wrapper.ToString();
context.Trace(response);
return response;
}</set-body>
</send-one-way-request>
<return-response>
<set-status code="200" reason="OK" />
</return-response>
</when>
<otherwise>
<return-response>
<set-status code="404" reason="Not Found" />
<set-body>Aeg-Event-Type header indicates unsupported event.</set-body>
</return-response>
</otherwise>
</choose>
</otherwise>
</choose>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Again, update the URL endpoints as needed in there!
- The location of your Spinnaker API (deck) endpoint for the webhook. This is always at
/webhooks/webhook/sourcename where I’ve used azureblob for the source but you could use whatever you want. The source name is used in the pipeline configuration for webhooks.
- The location of your Blob Storage and Blob Storage Proxy. These got set up earlier - in the
Replace call up there, you need to swap your Blob Storage server location for the location of your proxy so when Spinnaker tries to download, it’ll go through your proxy.
I’m not going to dive too deep into API policy management. I recommend reading the official docs and being aware of what is available. However, I will explain what this policy does and how it works.
Whenever something comes from EventGrid it includes an Aeg-Event-Type header. The two header values we’re concerned with are SubscriptionValidation and Notification.
If there’s no header, return a 404. Whatever the request wants, we can’t support it.
If the header is SubscriptionValidation, EventGrid wants a handshake response to acknowledge we expect the subscription and want to handle it. We grab a validation code out of the inbound request and return a response that includes the code as an acknowledgement.
If the header is Notification, that’s the actual meat of the subscription coming through. The data will be coming through in EventGrid schema format and will look something like this when it’s a “blob created” event:
[
{
"topic": "/subscriptions/{subscription-id}/resourceGroups/Storage/providers/Microsoft.Storage/storageAccounts/xstoretestaccount",
"subject": "/blobServices/default/containers/container/blobs/filename",
"eventType": "Microsoft.Storage.BlobCreated",
"eventTime": "2017-06-26T18:41:00.9584103Z",
"id": "831e1650-001e-001b-66ab-eeb76e069631",
"data": {
"api": "PutBlockList",
"clientRequestId": "6d79dbfb-0e37-4fc4-981f-442c9ca65760",
"requestId": "831e1650-001e-001b-66ab-eeb76e000000",
"eTag": "0x8D4BCC2E4835CD0",
"contentType": "application/octet-stream",
"contentLength": 524288,
"blobType": "BlockBlob",
"url": "https://oc2d2817345i60006.blob.core.windows.net/container/filename",
"sequencer": "00000000000004420000000000028963",
"storageDiagnostics": {
"batchId": "b68529f3-68cd-4744-baa4-3c0498ec19f0"
}
},
"dataVersion": "",
"metadataVersion": "1"
}
]
We need to transform that into a Spinnaker webhook format that includes artifact definitions. The artifacts coming from Azure Blob Storage will be HTTP File artifacts. It should like this:
{
"artifacts": [
{
"type": "http/file",
"reference": "https://mycoolproxy.azurewebsites.net/container/filename",
"name": "/blobServices/default/containers/container/blobs/filename"
}
]
}
- The
reference is the download URL location through your proxy to the blob.
- The
name is the subject of the EventGrid event.
The policy does this transformation and then forwards the EventGrid event on to your Spinnaker webhook endpoint.
You should now be able to POST events to Spinnaker via API Management. Using the example EventGrid body above or the one on the Microsoft docs site, make modifications to it so it looks like it’s coming from your blob store - update the locations, container name, and filename as needed. Use the “Test” mechanism inside Azure API Management to POST to your /webhook endpoint and see if it gets forwarded to Spinnaker. Make sure you add an Aeg-Event-Type header to the request or you’ll get the 404. Inside the test area you can see the trace of execution so if it fails you should see exception information and be able to troubleshoot.
Subscribe to EventGrid Blob Created Events
EventGrid needs to send events to your new API endpoint so they can be proxied over to Spinnaker.
In the Azure Portal, in the API Management section, take note of your API key for “Unlimited” - you associated this key with the API earlier when you created it. You’ll need it for creating the subscription.
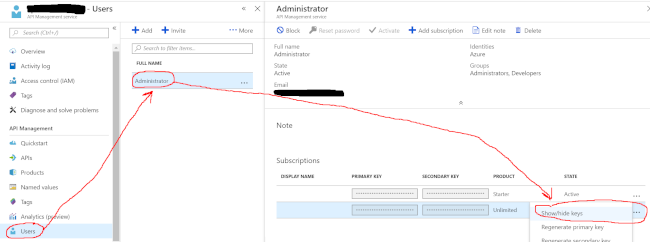
When you access your /webhook API endpoint, you’ll pass that key as a query string parameter: https://my-azure-api.azure-api.net/webhook?subscription-key=keygoeshere
It’s easier to create subscriptions in the Azure Portal because the UI guides you through the right combination of parameters, but if you want to do it via CLI…
az eventgrid event-subscription create \
--name spinnaker \
--endpoint-type webhook \
--included-event-types Microsoft.Storage.BlobCreated \
--resource-group myrg \
--resource-id /subscriptions/GUIDHERE/resourceGroups/myrg/providers/Microsoft.Storage/StorageAccounts/myartifacts \
--endpoint https://my-azure-api.azure-api.net/webhook?subscription-key=keygoeshere
You only want the Microsoft.Storage.BlobCreated event here. If you create or overwrite a blob, the event will be raised. You don’t want the webhook to fire if you delete something.
This may take a few seconds. In the background, EventGrid is going to go do the handshake with API Management and the policy you put in place will respond. This is easier to watch in the Azure Portal UI.
You now have Azure Blob Storage effectively raising Spinnaker formatted webhooks. Azure Blob Storage causes EventGrid to raise a webhook event, API Management policy intercepts that and transforms it, then it gets forwarded on to Spinnaker. You can trigger pipelines based on this and get artifacts into the pipeline.
Test the Full Circle
Here’s what I did to verify it all worked:
Create a simple Helm chart. Just a Kubernetes Deployment, no extra services or anything. You won’t actually deploy it, you just need to see that some sort of retrieval is happening. Let’s say you called it test-manifest so after packaging you have test-manifest-1.0.0.tgz.
Create a simple pipeline in Spinnaker. Add an expected artifact of type http/file. Specify a regex for “Name” that will match the name property coming in from your webhook. Also specify a “Reference” regex that will match reference.
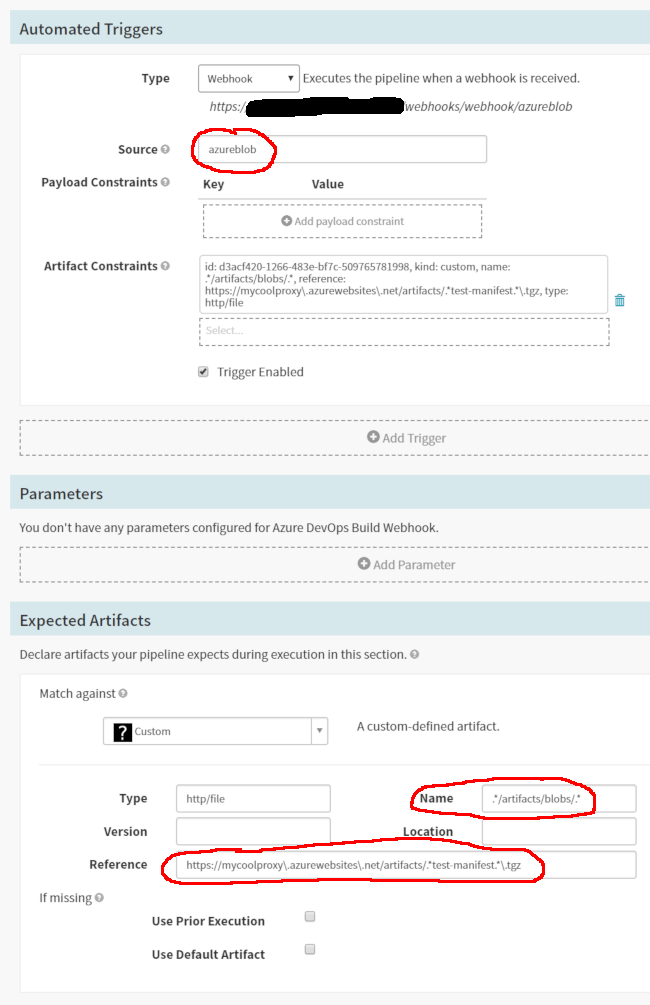
In the “Automated Triggers” section, add a webhook trigger. Give it a source name that lines up with what you put in the API Management policy. In the example, we used azureblob. Also add an artifact constraint that links to the expected artifact you added earlier. This ensures your pipeline only kicks off if it gets the artifact it expects from the webhook payload.
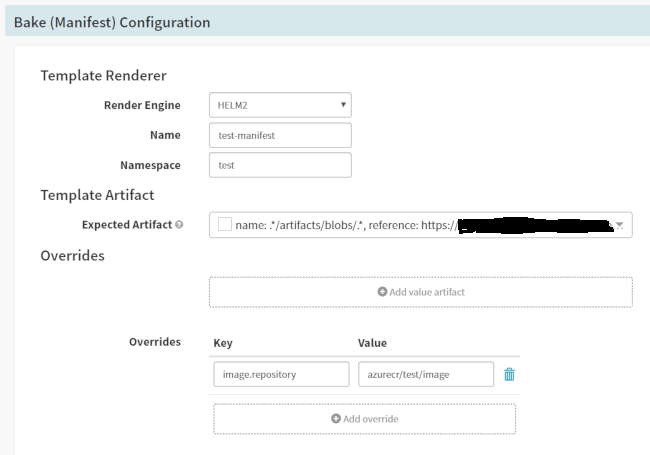
In the pipeline add a “Bake (Manifest)” step. For the template artifact, select the .tgz artifact that the webhook will be providing. Fill in the name and namespace with whatever you want. Add an override key that will be used in the template process.
Now use the Azure Portal to upload your test-manifest-1.0.0.tgz “artifact” into your Azure Blob Storage container. This should cause the webhook to be raised, eventually making it to Spinnaker. Spinnaker should see the artifact, kick off the pipeline, and be able to download the Helm chart from Blob Storage so it can run the Helm templating step.
On the finished pipeline, you can click the “Source” link in the Spinnaker UI to see a big JSON object that will contain a huge base-64 encoded artifact that is the output of the “Bake (Manifest)” step. If you decode that, you should see your simple Helm chart, templated and ready to go.
Troubleshooting
What do you look at if it’s not working? There are a lot of moving pieces.
- Verify the credentials you configured in Spinnaker. The username should be the blob storage account name and the password should be the shared key you got out of the Azure Portal. Try doing a download through your HTTP Basic proxy using those credentials and verify that still works.
- Run a test in API Management. The “Test” section of API Management lets you simulate an event coming in from EventGrid. Use the “Trace” section in there to see what’s going on and what the response is. Did the transformation fail?
- Look at Spinnaker “echo” and “deck” pod logs. I’m a big fan of the
stern tool from Wercker for tailing logs of pods. It’s easy to watch logs in real time for doing something like: stern 'spin-(echo|deck).*' -n spinnaker -s 5s Make a test request from API Management and watch the logs. Do you see any errors fly by?
- Ensure you haven’t changed any keys/names. The Azure Blob Storage key, the API Management key, the source name in the Spinnaker webhook… all these names and keys need to line up. If you rotated keys, you need to update the appropriate credentials/subscriptions.
- Is something timing out? If you don’t have the “Always On” feature for your Azure Blob Storage proxy, it will go to sleep. The first request will cause it to wake up, but it may not be fast enough for Spinnaker and the request to download may time out.
Next Steps
By now you should have things basically working. Things you could do to make it better…
- Test with large files. I didn’t test the Azure Blob Storage proxy thing with anything larger than a few hundred kilobytes. If you’re going to need support for gigabytes, you should test that.
- Add security around the Spinnaker webhook. The Spinnaker webhook endpoint doesn’t have any security around it. There’s no API key required to access it. You could make the “source” for the webhook include some random key so no hook would be raised without matching that source. If you have to rotate it that might be a challenge. This also might be something to file as an enhancement on the Spinnaker repo.
- Add security around the Azure Blob Storage proxy. You definitely need to have your basic creds in place for access here, and you need valid credentials for a storage account… but (at least in the Astbury blog article) there’s no limit on which storage accounts are allowed. You might want a whitelist here to ensure folks aren’t using your proxy to access things you don’t own.
